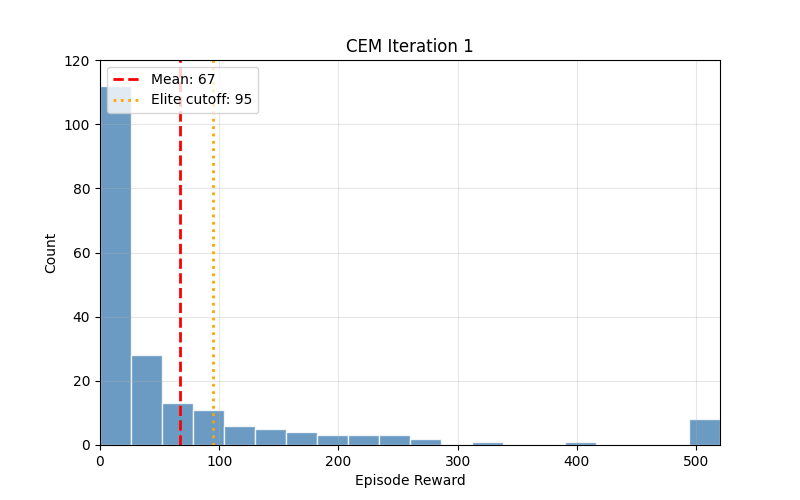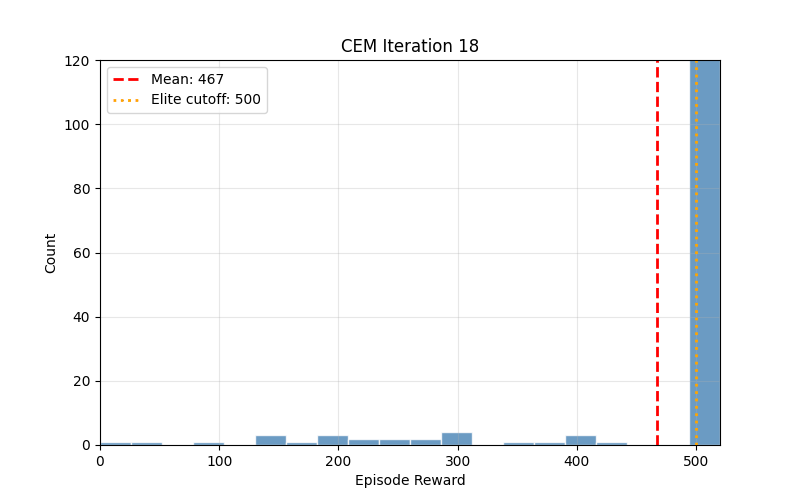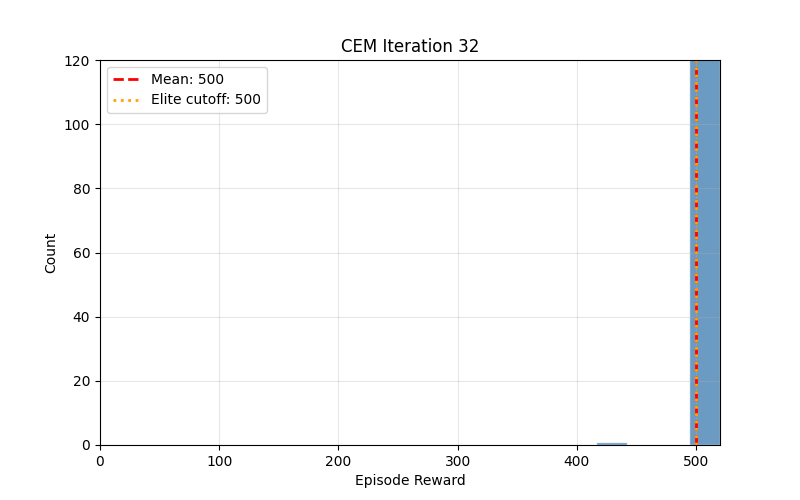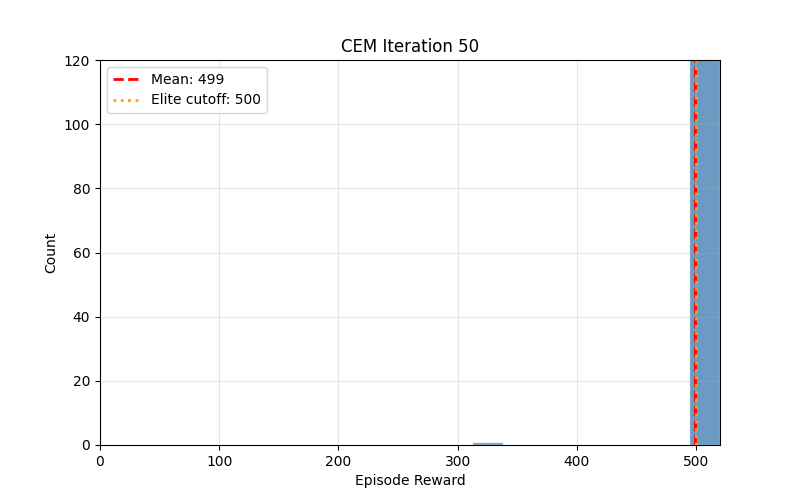
Reinforcement learning has accumulated layers of complexity over the years: value functions, policy gradients, replay buffers, target networks. The Cross-Entropy Method predates all of it. Rubinstein introduced it in 1997 for rare-event simulation, and it turned out to solve simple control tasks with almost no machinery.
The entire implementation fits in 50 lines. No gradients, no training loops.