How to turn generic evaluation metrics into a useful starting point for AI Reliability. It's common now with all the talk about AI reliability to come to a bit of a conundrum: you know quality matters, but you don't yet know which failures matter most. You deploy a handful of broad evaluations like toxicity, hallucination, response length, and hope they catch the important stuff. Often what you fi
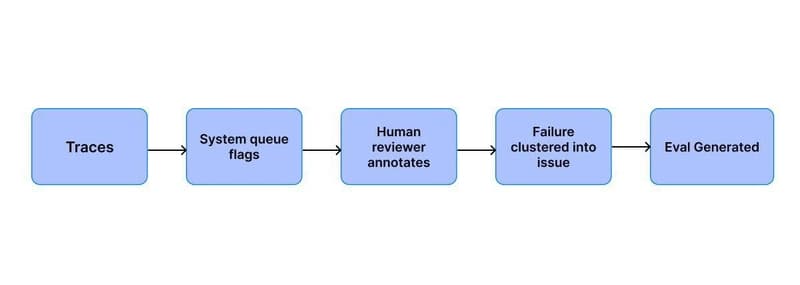
From Generic Evals to Specific Monitors: The Annotation Queue Bridge
Paula Cavero·Dev.to··1 min read
D
Continue reading on Dev.to
This article was sourced from Dev.to's RSS feed. Visit the original for the complete story.