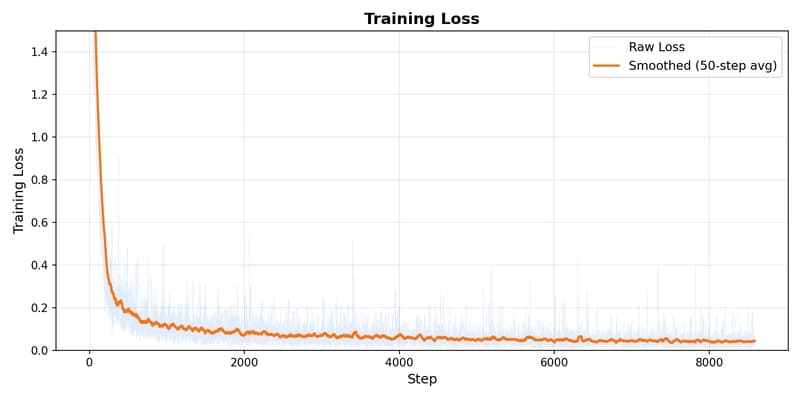
A fine-tuning post-mortem, and three tests that showed me what my model actually learned. Today I fine-tuned Google's gemma-4-E2B-it on the unsloth/LaTeX_OCR dataset using LoRA on a RunPod RTX 3090. Nine hours of training, about $2 in GPU cost, and an adapter uploaded to Hugging Face.
The training loss dropped from 13.66 to 0.018. On the test set, the outputs were near-perfect. Then I ran three te