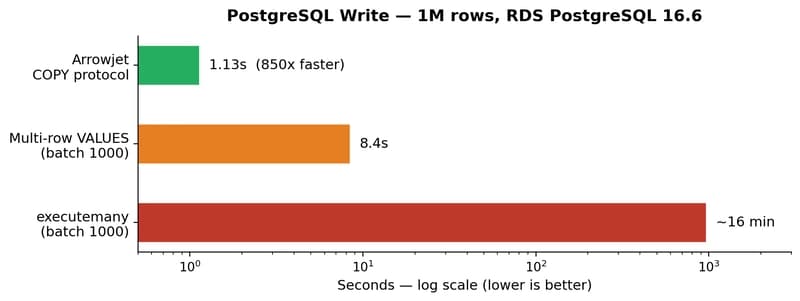
Every Python developer loading data into PostgreSQL hits the same wall. executemany() with 1M rows? 16 minutes. df.to_sql()? Same thing — it generates INSERT statements under the hood. Even method='multi' with chunking is slow because each batch is still a SQL statement parsed by the server.
PostgreSQL has had a faster path since version 7.x: the COPY protocol. It bypasses the SQL parser entirely