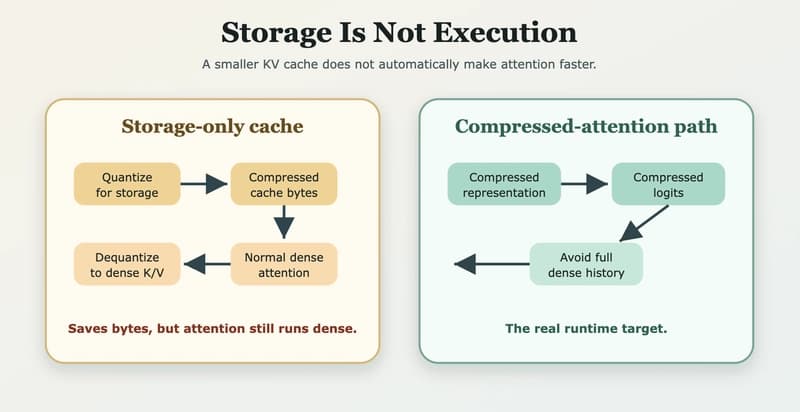
Long-context generation makes the KV cache hard to ignore. Every generated token reuses keys and values from previous tokens. As the context grows, those cached tensors grow with it.
So the natural first idea is simple: Compress the KV cache, store fewer bytes, and get faster generation. We tested that idea while exploring TurboQuant-style cache compression in a Hugging Face transformers fork. I