If you work with Pandas, PyArrow, DuckDB, Spark, Polars, or data APIs, you’ve probably heard that Apache Arrow is fast because it is in-memory and columnar. That’s true, but just like Parquet, the real value starts to click when you understand how Arrow is physically organized. Under the hood, an Arrow file is not just “serialized table data.” It is a structured binary format built around schemas,
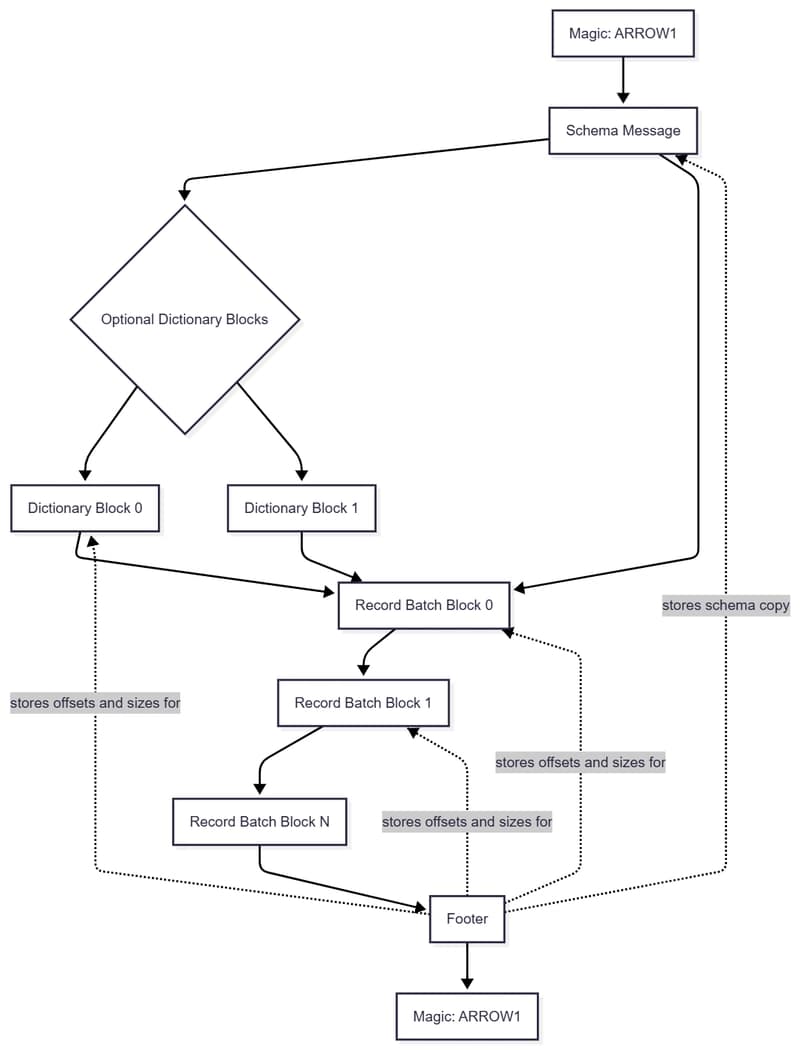
Apache Arrow File Anatomy: Buffers, Record Batches, Schemas, and IPC Metadata Explained 🏹📦
Kumaravelu Saraboji Mahalingam·Dev.to··1 min read
D
Continue reading on Dev.to
This article was sourced from Dev.to's RSS feed. Visit the original for the complete story.