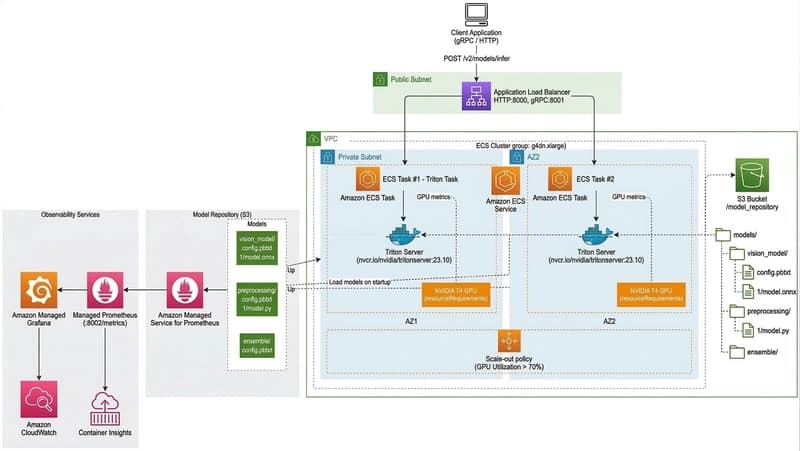
“Why is it so slow even though I have a GPU?” I’d like to share my three-week struggle, which began with this single question. Introduction While developing the Vision AI service, I chose Nvidia Triton Inference Server as the framework for model serving. Its features—such as multi-framework support, dynamic batching, and ensemble pipelines—were excellent, and I was particularly drawn to its ab
The Struggle to Optimize the Performance of the NVIDIA Triton Inference Server Running on AWS ECS
Yeonggyoo Jeon·Dev.to··1 min read
D
Continue reading on Dev.to
This article was sourced from Dev.to's RSS feed. Visit the original for the complete story.