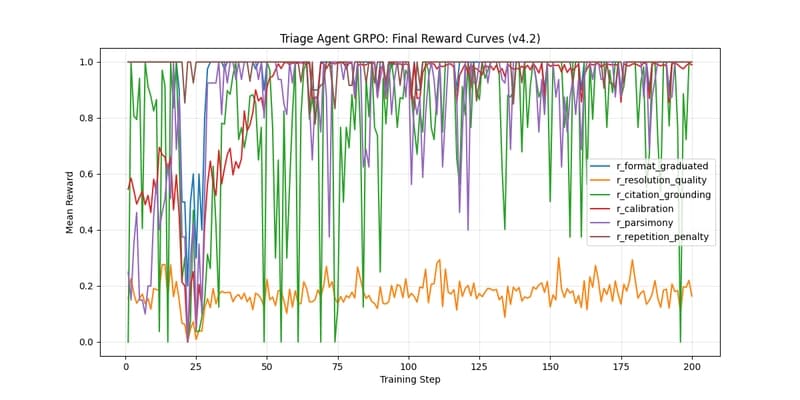
A Sunday-morning postmortem on teaching a 3B model to do enterprise IT triage with GRPO. It's 1 AM on a Sunday. The Meta × PyTorch OpenEnv Hackathon submission is due at 5 PM.
My training logs show a loss curve that's been flat at 0.0 for the last thirty minutes. A flat loss in supervised learning means convergence. A flat loss in reinforcement learning usually means something else: your model has